by Richard G. Baldwin
baldwin@austin.cc.tx.us
Baldwin's Home Page
Dateline: 07/18/99

As of the date of this writing, this site provides qualified links to more than 800 XML resources, and the number of links is growing every day. Creating and maintaining such a site could be a full-time job for someone if they didn't approach the task in a systematic way.
I am a college professor and private consultant who maintains this site in his spare time. I have developed an XML-based software system that allows me to maintain the site without interfering with my ability to carry out my other responsibilities.
In the previous article, I showed you how to use SAX to convert an XML document into a set of Java objects, and how to convert a set of Java objects into an XML document.
I promised that in this article, I would show you more of the Java code that can be used to convert the XML file into a set of Java objects using SAX. I will get back to that and will eventually keep my promise.
To avoid the risk of putting you to sleep while reading about dry Java code, I decided to interrupt that discussion and present a real-life example of why you might want to do this sort of thing.
I use XML and Java every day for the purpose of maintaining this site. I store all of the links to XML resources in an XML database and have written several Java programs to manipulate and maintain that database.
Also, in order to evaluate XML resources more efficiently, I have written Java programs that automatically pre-screen all potential XML resources before I take the time to evaluate them personally.
The following sections discuss the process that I generally use to evaluate and post XML resources on this site.
The first step in the process is to develop a large list of candidate resources (500 to 1000) using typical web searching procedures. This typically involves collecting successive pages from the output of a web search engine or collecting a group of web sites that claim to contain links to useful resources.
The collection process simply involves saving the web site pages on the local hard drive using the SaveAs feature of the browser. The output from this step is a set of HTML files that may contain useful links. Depending on other factors, I typically begin with from one to twenty such files. If those pages came from a search engine, each page will typically contain from ten to fifty candidate links.
When I do my original search using a search engine, I construct my search criteria as well as I can. For example if my emphasis on that day has to do with DTDs and schema in XML, I might search for xml AND dtd AND schema
Unfortunately, at the current state of the art of web searching, such a search will typically produce hundreds and sometimes thousands of "hits", a very large percentage of which are worthless.
(As an aside, on this site you will find links to several articles that explain how the use of XML can improve web search capabilities in the future.)
On 7/16/99, the search described above produced 684 hits on the Excite search engine, while the same search at Yahoo produced 1250 hits. Whether the number is 684 or 1250, it is still overwhelming for a person trying to find the best resources on a topic of interest.
The HTML files collected in the first step will usually contain duplicate URLs, links to advertising banners, and other such unproductive material. Even more important, they will frequently contain many links to resources that I have already posted on my site, which I don't need to evaluate again.
The second step uses a Java program that I have written to automatically scan the candidate list to eliminate duplicate links and to eliminate resources from the list that already exist in my XML database.
The program also eliminates links to advertising banners and other forms of garbage. This process produces a single output HTML file containing a list of "clean" links to candidate resources.
While the links on this list are "clean", and don't already exist in my database, they are not necessarily useful and don't necessarily merit posting on my site. I use a combination of additional automatic screening and personal evaluation to determine if a resource merits posting on my site.
Many of the resources in the "clean" list produced by the previous step may be based on old search engine data, and may not even still exist. In addition, many of the links on the list will have been included in the output of a search engine due to meta keyword traps, and may not contain any useful information about my topic of interest at all. Many of them will be top-level pages from a large site that will mention my topic on a site map, or somewhere else on the page, but will not contain any substantive information about my topic.
The next step uses a Java spider program that I have written to automatically download each of the resources from the "clean" list and to automatically evaluate them against a quality criteria that I have developed. The purpose is to determine if it would be worth my while to personally evaluate one or more of those resources.
This process applies the quality criteria screen to the content of the <BODY>...</BODY> element of the HTML page and discards the rest. Therefore it eliminates meta keywords that are designed to trap search engines. This simple process alone eliminates many candidate resources that are obtained from search engines.
The qualification process runs in the background and can be performed concurrently with the next step, which is to personally evaluate those resources that survive all of the automatic screening. The output from the qualification step is a set of HTML files stored locally on the hard drive. They can be quickly loaded into my browser for personal evaluation without the requirement to waste time waiting for a network connection.
Typically, the number of candidate resources will have been reduced by a factor of ten or more from an original hit list produced by a search engine, so an original search engine output containing 1000 hits will have been reduced to perhaps 100 or fewer resources requiring personal evaluation.
A very important point is that I don't expend my time evaluating a resource until it has survived this series of automatic screens. This allows me to invest my personal time in a more effective manner than would otherwise be the case.
Frequently this process turns up pages containing links to other resources. What do I do with them? Simple, I just feed them back around to the front end and run them through the automatic screening process again to extract the useful links from those pages as well.
As mentioned earlier, this overall screening process can be applied not only to search engine output, but also to any HTML file that is believed to contain a list of useful XML links. This includes such material as web sites that read "Hello, my name is Joe, and here is my list of useful XML links."
The next step is to personally evaluate the candidate resources that have survived the automated screening, and to enter them into the XML database.
At this point, an HTML file for each of the candidate resources exists on my hard drive. Each file can be quickly loaded into my browser for examination. This is where I spend the bulk of my time and effort. The objective of the system that I have developed is to allow me to concentrate on content rather than to expend time and effort in other non-productive ways (such as waiting for a connection to a web site, or editing large numbers of HTML files).
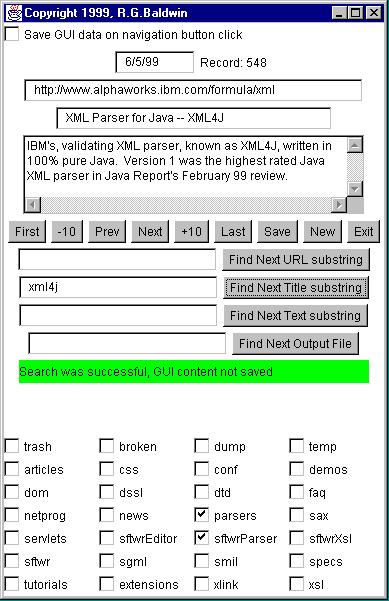
In order to describe this step more fully, I will need to describe how I use the XML database. This can probably best be accomplished by showing and discussing a screen shot of the Graphical User Interface (GUI) to the XML editor program that I have developed specifically for this purpose.
The following image is a screen shot of the XML editor GUI showing a display of one of the resources in the XML database. Keep in mind that when I have this GUI on my desktop, I also have an open browser window containing a local copy of a candidate web site that I am evaluating.
I will explain the process by explaining each of the items on the GUI. You might find it useful to open this image in a separate browser window so that you can view it while reading the discussion.
This legend appears next to the checkbox in the upper left-hand corner of the GUI.
There are two ways to cause the data currently showing in the GUI to be saved into the XML database, possibly overwriting a data record already stored there. The safest way is to click the Save button near the center of the GUI. This is a one-shot save and allows very close control over the possibility of overwriting existing records.
The checkbox in the upper left-hand corner is provided for those situations where it is always desired to save the data currently showing in the GUI when navigating to a different record, even if that means overwriting an existing record in the database.
Although I don't use this feature very often, it is sometimes useful for wholesale editing operations while navigating through the database, perhaps on the basis of one of the search buttons that I will discuss later.
The GUI contains about eight text fields that serve the dual purpose of data entry fields for new records and display/edit areas for existing records. The top three of these fields show the record origination date, the URL, and the Title respectively for record number 548. (The record number is displayed immediately to the right of the date.)
The date field reflects the date on which the record was created and entered into the database. It is somewhat different from the other text fields in that its contents are automatically created from the computer's system clock on the day that the record is created. However, this field is fully editable, so it is possible to modify the date if you want to.
There is another important capability of the system, having to do with a new icon, which is tied to this date field. Although I haven't mentioned it before, the final step in the process is to run a Java program that I have written that creates a new set of HTML files corresponding to the data in the database. These files are then uploaded to my site and are what you see when you browse my site.
In other words, except for a couple of top-level HTML files, all of the HTML files on my site are automatically generated on the basis of the data in my XML database. This virtually eliminates the problem of creating errors when manually editing HTML files.
When the database is converted to the representative set of HTML files for uploading, the program automatically places new icons on all of the links that are less than fourteen days old. (The icon is automatically removed from a link when it becomes fourteen days old.)
This solves a major logistics problem associated with maintaining the site manually; trying to remember to first add, and later remove the new icon from new links.
If you browse my XML site near the publication date of this article, you will find hundreds of links showing new icons. This is the result of the rapid growth of this site during its formative stages.
The next two fields on the GUI show the URL and the Title for a resource. For this particular example, they show the URL and Title for an IBM alphaWorks resource for the XML4J parser.
All of the text fields support cut, copy, and paste operations. Therefore, it is never necessary to manually enter complex URLs. I simply copy them from the browser window onto the clipboard, and then paste them into the URL field of the XML editor. This eliminates a lot of broken links resulting from typing errors while manually editing HTML files containing the URLs.
The width of the title field is approximately correct for a title that meets the display specifications for link titles. In other words, if the title will fit in the text field shown, it will probably meet the width specification. This is a very useful feature because it allows me to gauge how much information I can include in a title without causing the title to be too wide.
The large text area with the scroll bars is a Java TextArea object. The physical size of this text area was also designed to be approximately correct for the width and height specifications for the descriptive text that appears with the link. In other words, if the text will fit in this area, it will probably satisfy the specification for the width and the number of lines in the description of a link.
I have provided special code in a TextEvent handler for this TextArea component that does a lot of cleanup on text that I copy from a web page and paste into this area (such as elimination of multiple space characters, repositioning of word wrap, etc.). This helps to reduce the manual keyboard effort when creating the descriptive text for the link.
The nine buttons immediately below the descriptive text area are used to navigate through the XML database for editing purposes. Although the use of these buttons is probably intuitive, brief descriptions of the behavior of each of the buttons follows:
Upon startup, the program automatically produces and verifies a backup file matching the XML file that contains the unedited database. Thus, following an editing session, two files are available, one from before the editing session, and one from after the editing session.
When the site contains links to several hundred resources, it is sometimes difficult to remember if a new candidate resource is already posted on the site.
The first step in the pre-screening process discussed earlier eliminates the possibility of duplicates in the database for the same URL. However, many worthwhile XML resources appear at multiple locations on the web under different URLs, so elimination on the basis of URL alone is not sufficient to prevent duplicates.
Although I have a manual approach for dealing with this problem that I will discuss later, I haven't devised a fully-automated method of screening out duplicates of this type without the risk of also screening out non-duplicates (but I am working on it).
In the meantime, the best mechanism that I have to avoid posting duplicate links of this sort is to make it easy to search the database for duplicates on some basis other than the URL. Even with the capability to search the database, I still sometimes end up posting duplicate links. My attitude is that it is better to have a few duplicate links among many resources than it is to expend the time and effort to completely avoid duplicate links, when that time and effort could be better spent finding and qualifying new resources.
The four text/button combinations immediately below the navigation buttons provide such a search capability for URL, Title, Text Description, and Output File (I will defer the discussion of Output File until later).
This is a substring search that is useful for many purposes. Suppose for example that I would like to examine all of the records in the database for which the URL contains "alphaworks". (Because of IBM's active participation in XML, there are several different records in the database that meet this criteria.) The process is very simple:
This will move the record counter to the first record meeting the search criteria and display the data contained in that record. If I want to see the next one, I simply click the button again.
Each of the search fields operates in this manner.
Immediately below the search fields is a colored status bar that displays various kinds of information and colors depending on the previous operation.
In the example case shown in the GUI, the status shows that the search for xml4j in the Title field was successful, and the data showing in the GUI before changing the record counter was not saved.
(As mentioned earlier, the checkbox in the upper left-hand corner can be selected to cause the data showing in the GUI to always be saved when the record counter changes.)
The editing program produces a single backup file and a single edited output file. They are XML files containing the unedited and edited versions of the database.
As I mentioned earlier, a later process produces a new set of HTML files that contain the data from the XML database. These are the files that are uploaded to my site, and it is this set of HTML files to which this discussion relates.
Although I haven't mentioned it before, the operation of this editing program, and other programs in the system, depend on two XML files, not just one.
One XML file contains the resource data that I have been discussing up to this point. (As of the date of this writing, it is about 400KB in size.)
A second, and much smaller XML file contains information about the HTML files that will ultimately be created for uploading to my site. (As of the date of this writing, it is about 14KB in size.)
This smaller file contains the name of each HTML file, and also contains additional information for each HTML file such as meta keywords, title, description, etc. In other words, the smaller XML file contains all of the information necessary to produce the skeleton set of HTML files that will be populated using data from the XML database for uploading to my site.
When the editor program starts up, it reads the small XML file containing file-name data and produces the grid of checkboxes that you see on the bottom of the GUI. The more files there are, the more checkboxes will be produced, because there is one checkbox for each HTML file.
The names associated with the checkboxes are derived from the file names in the XML file. If I add a new record to the small XML file describing a new HTML file, a new checkbox corresponding to that file will appear in the GUI. Similarly, if I remove a record from the XML file, the corresponding checkbox will disappear from the GUI.
I'm going to jump ahead and give you the bottom line, and then come back and discuss the overall situation in more detail.
As you can see from the above screen shot, this record has check marks for "parsers" and "sftwrParser". This means that when the set of HTML files is automatically generated and uploaded to my site, the resource described by this record will appear in two different categories. One category provides links to information about parsers in general. The other category provides links to specific parser software that is available.
No matter which category you select, you will have access to the link to the parser software. On the other hand, a resource that simply discusses how to use parsers in general to process XML documents would appear only in the category on parsers.
You may or may not agree with this organizational structure for parser information, but that is beside the point for this discussion. This is a relatively new site, and I am still working to categorize the resources into the best possible structure for the users. I will be improving the structure over time.
The point to this discussion is that if I were to decide to eliminate the "sftwrParser" category tomorrow and move those resources into some other category, such as simply "sftwr", I could accomplish that in ten or fifteen minutes at the outside.
I would use the bottom search box to find each record currently checked for "sftwrParser", clear that checkmark, select the checkmark for "sftwr", and click the Save button. Upon Exit, that action would move each of those records out of the "sftwrParser" category and into the "sftwr" category.
Then I would remove the data record describing the HTML file for "sftwrParser" from the small XML file, and the next time I did a system update, that file would not be generated.
Contrast this with the prospect of manually moving several dozen sections of HTML text from one HTML file to another, while making certain to insert the HTML text items in alphabetical order in their new home. I'm not very good at editing HTML, so this would take me quite a while to accomplish, including the time required to fix the problems that I would undoubtedly create.
To finalize the modification, it would also be necessary for me to manually edit two different top-level HTML files that refer to the "sftwrParser" file, but someday I will probably automate that process as well.
Now that you have seen the bottom line, let's step back and discuss some other considerations.
Basically, I consider the XML resource data in the database to be subdivided into two major categories, plus three or four less-important categories.
The two major categories are the keepers and the dumpers
The keepers are those XML resources that you will see when you browse my XML site.
The dumpers are resources that I have evaluated, and which are maintained in the database, but which you will not see when you browse my XML site.
Given the thousands of XML resources currently on the web, my attitude is that I should expend time and energy to evaluate a web resource only once in my lifetime (unless I have reason to believe that it has improved over time). If I evaluate it and find it to be a keeper, I assign it to one or more of the output file categories that cause it to appear on my site.
If I evaluate it to be a dumper, then I don't ever want to see it again.
As I mentioned earlier in this article, my first automatic screening process eliminates all candidates whose URL already exists in my XML database. This is true whether the resource is a keeper or a dumper, and elimination of that resource from the list of new candidates satisfies my objective in both cases. Either way, the resource doesn't make it through the first automatic screening process so I don't have to waste time evaluating it again.
There are a number of reasons that I would categorize a candidate resource as a dumper. One obvious reason is that it simply doesn't contain the kind of quality information that I want to guide you to. There are a lot of resources like that on the web.
Another very common reason is that it is a URL that refers to a different copy of a resource that has previously been categorized as a keeper under a different URL. In this case, which is very common, it represents a duplicated resource that I want to automatically screen out at the first step in the automatic screening process.
If you refer back to the bottom of the GUI, you will see a checkbox labeled dump. All that I have to do to put a resource in the dumper category is to enter its URL in the URL field, check the dump checkbox, and click the Save button. Everything else is handled automatically.
As of this writing, the database contains more than 500 dumpers.
You will also see checkboxes for trash, broken, and temp. To delete a record, I put it in the trash category. Later I run a trash collector program that removes all records in the trash category from the database.
If I discover that a link to a resource has become broken because the resource has been moved or for any other reason, I temporarily move the record to the broken category. This removes it from display on my site while giving me an opportunity to investigate the situation. For example, sometimes, I can find another copy of the same resource somewhere else on the web and can reinstate the resource by changing the URL field and restoring it to its previous category.
As you might have suspected, I use the temp category as a temporary holding area for resources that need further qualification before being categorized as either keepers or dumpers.
Because I have the ability to search the database on these output file names, it is easy for me to locate, and possibly modify the status of a resource that has been placed in one of these categories.
The trash, broken, dump, and temp categories are used as utility categories to help me maintain the site. Resources that have been placed in these categories do not appear on my site.
The keepers are the resources that are placed in any category other than trash, broken, dump, or temp.
As of this writing, my XML web site provides about 24 HTML pages that correspond to the checkboxes and which link to more than 800 different XML resources. I expect the number of resources to grow into the thousands, and the number of different keeper categories to expand to several dozen over time.
In order to make this volume of resources useful to the viewer, it will be necessary for me to subdivide categories and produce a hierarchical structure for locating a resource. Although I won't go into the details of how I will do this, my editor was designed with this in mind. It isn't difficult for me to subdivide a category into two or more sub-categories and to move all of the resources from the original category into the new sub-categories. It is mostly a matter of point and click inside the editor.
As discussed earlier, some of the keepers fall into more than one category, which causes them to appear on more than one of the HTML pages on my site.
Could I have accomplished all of the above in other ways? Certainly!
For example, I could have used an SQL database for storage of the data, and I could have written the programs in C or C++. In doing so, however, I would have lost a lot of platform independence.
My current system runs on any platform that has a Java virtual machine at the JDK 1.2 level and that has a suitable parser library installed, such as IBM XML4J. This includes Windows, Linux, Solaris, MAC, and probably other platforms that I'm not familiar with.
I carry the entire software system and all of the data, back and forth between my home and my office on a daily basis on a zip disk. If I wanted to, I could switch back and forth between my Windows machine and my Linux machine.
Had I used SQL in conjunction with either C or C++, such transportability would be much more difficult to achieve
So there is a purpose to all of this talk about XML, Java, Sax, DOM, parsers, etc. These technologies really can be used in beneficial ways.
You too can search the web more effectively. All you need is knowledge of XML and Java programming.
I find it especially intriguing that in this case, I am able to make effective use of XML, SAX, XML4J, and Java programming to lead others to valuable resources about XML, SAX, XML4J, and Java programming.
There must be a word for this, but I don't know what it is.
|
coming attractions... |
My plan for the next article is to get serious again, and resume the programming discussion, showing you more of the Java code that can be used to convert the XML file into a set of Java objects using SAX.

Trying to wrap your brain around XML is sort of like trying to put an octopus in a bottle. Every time you think you have it under control, a new tentacle shows up. XML has many tentacles, reaching out in all directions. But, that's what makes it fun. As your XML host, I will do my best to lead you to the information that you need to keep the XML octopus under control.
This HTML page was produced using the WYSIWYG features of Microsoft Word 97. Some of the images on this page were used with permission from the Microsoft Word 97 Clipart Gallery.
151406
Copyright 2000, Richard G. Baldwin
baldwin@austin.cc.tx.us
Baldwin's Home Page
-end-